网络编程
本指南深入探讨网络编程的复杂性、涵盖协议、TCP/UDP套接字、并发等内容
关键概念
- 网络协议 Networking Protocols
- TCP (Transmission Control Protocol): 确保可靠的数据传输
- UDP (User Datagram Protocol): 速度更快,但不能保证数据的可靠传输
- 套接字 Sockets
- TCP Sockets: 用于面向连接的通信
- UDP Sockets: 用于无连接通信
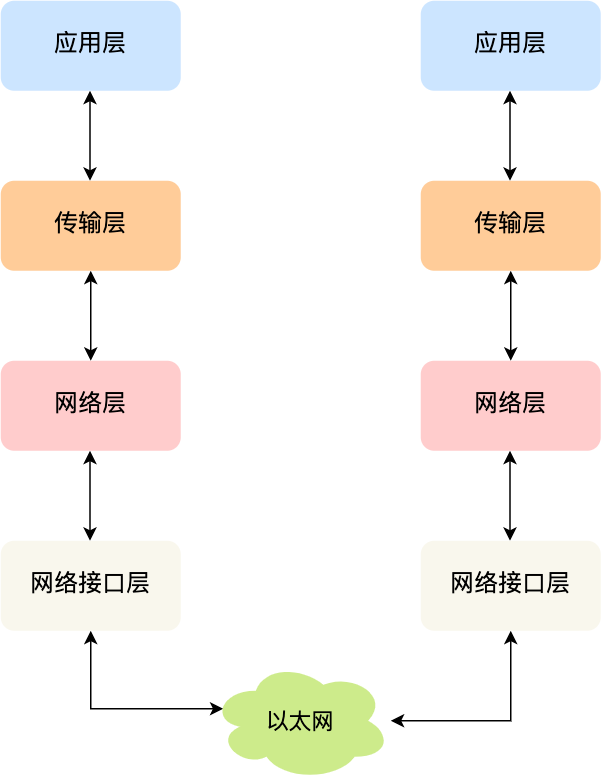
TCP/IP 网络模型
同一台设备进程间通信: 管道、消息队列、共享内存、信号
不同设备进程间通信: 需要网络通信,为了兼容多种多样的设备,需要一套通用的网络协议
应用层 (Application Layer)
应用层只需要专注用户提供应用功能,比如HTTP、FTP、DNS、SMTP, 应用层是不需要关心数据是如何传输的,以及应用层工作在操作系统中的用户态,传输层及以下则工作在内核态
传输层 (Transport Layer)
应用层的数据包会传输给传输层,传输层是为应用层提供网络支持, 传输层的两个传输协议,分别是TCP(Transmission Control Protocol)和UDP.
TCP-传输控制协议,TCP相比UDP多了很多特性,比如流量控制、超时重传、拥塞控制等,这些都是为了保证数据包能可靠地传输给对方.
UDP-相对简单,只负责发送数据包,不保证数据包是否能抵达对方,但实时性相对更好,传输效率更高
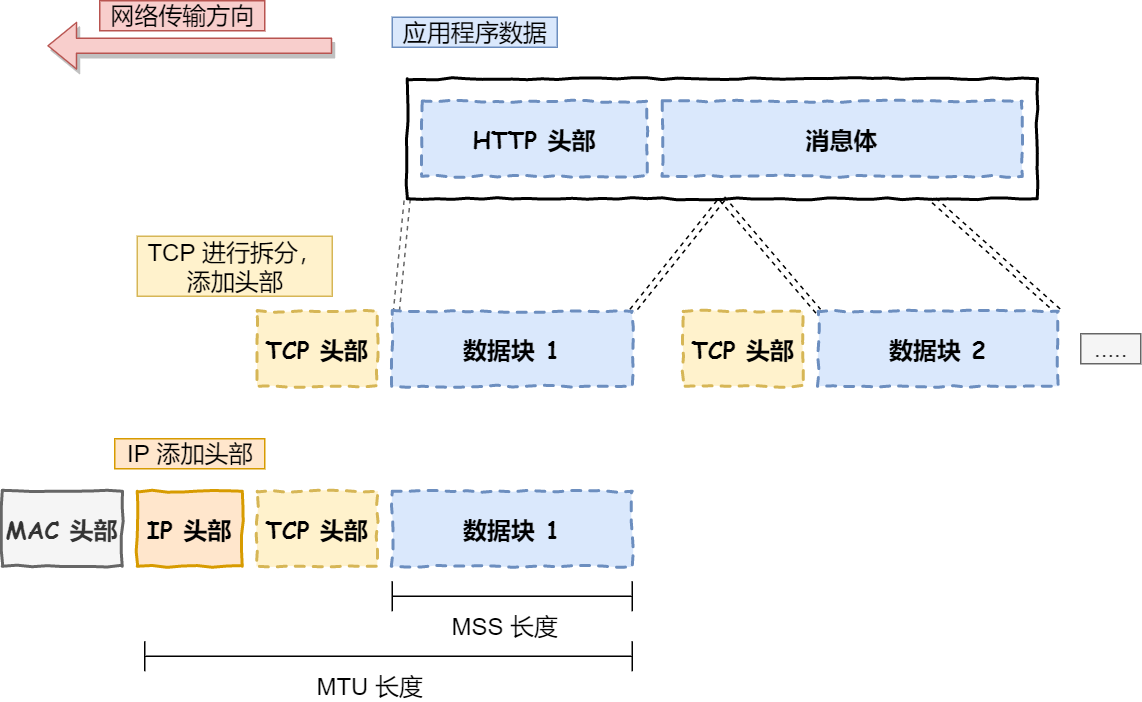
当数据包大小超过MSS(TCP最大报文段长度)就要将数据包分块.这样即使中途有一个分块丢失或损坏,只需要重新发送这个分块,而不用重新发送整个数据包. TCP协议中,每个分块称为一个TCP段(TCP Segment).
网络层 (Internet Layer)
网络层最常使用的是IP协议(Internet Protocol),IP协议会将传输层的报文作为数据部分,再加上IP包头组装成IP报文,如果IP报文大小超过MTU(以太网中一般为1500bytes)就会再次分片.
使用IP地址给设备进行编号,IP地址分成以下两种:
- 网络号: 负责标识IP地址是属于那个【子网】的
- 主机号: 负责标识同一[子网]的不同主机
1 | |
网络接口层 (Link Layer)
网络接口层在IP头部的前面加上MAC头部,并封装成数据帧(Data Frame)发送到网络上, MAC头部是以以太网使用的头部,它包含了接收方和发送方的MAC地址等信息,通过ARP协议获取对方的MAC地址.
网络接口层主要为网络层提供[链路级别]传输的服务,负责在以太网,WI-FI这样的底层网络上发送原始数据包,工作在网卡这个层次,使用MAC地址来标识网络上的设备.
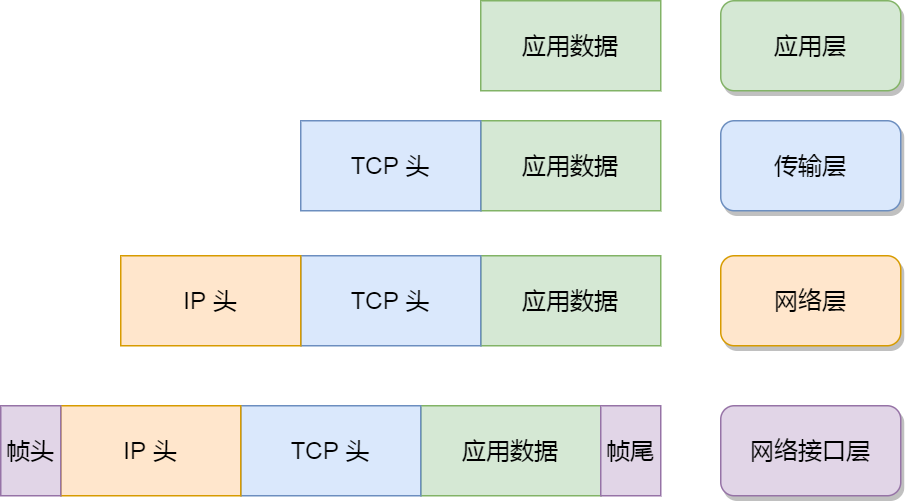
每一层的封装格式: 网络接口层的传输单位是帧(frame), IP层的传输单位是包(packet),TCP层的传输单位是段(segment),HTTP的传输单位则是消息(message)
输入网址到网页显示,期间发生了什么?
HTTP
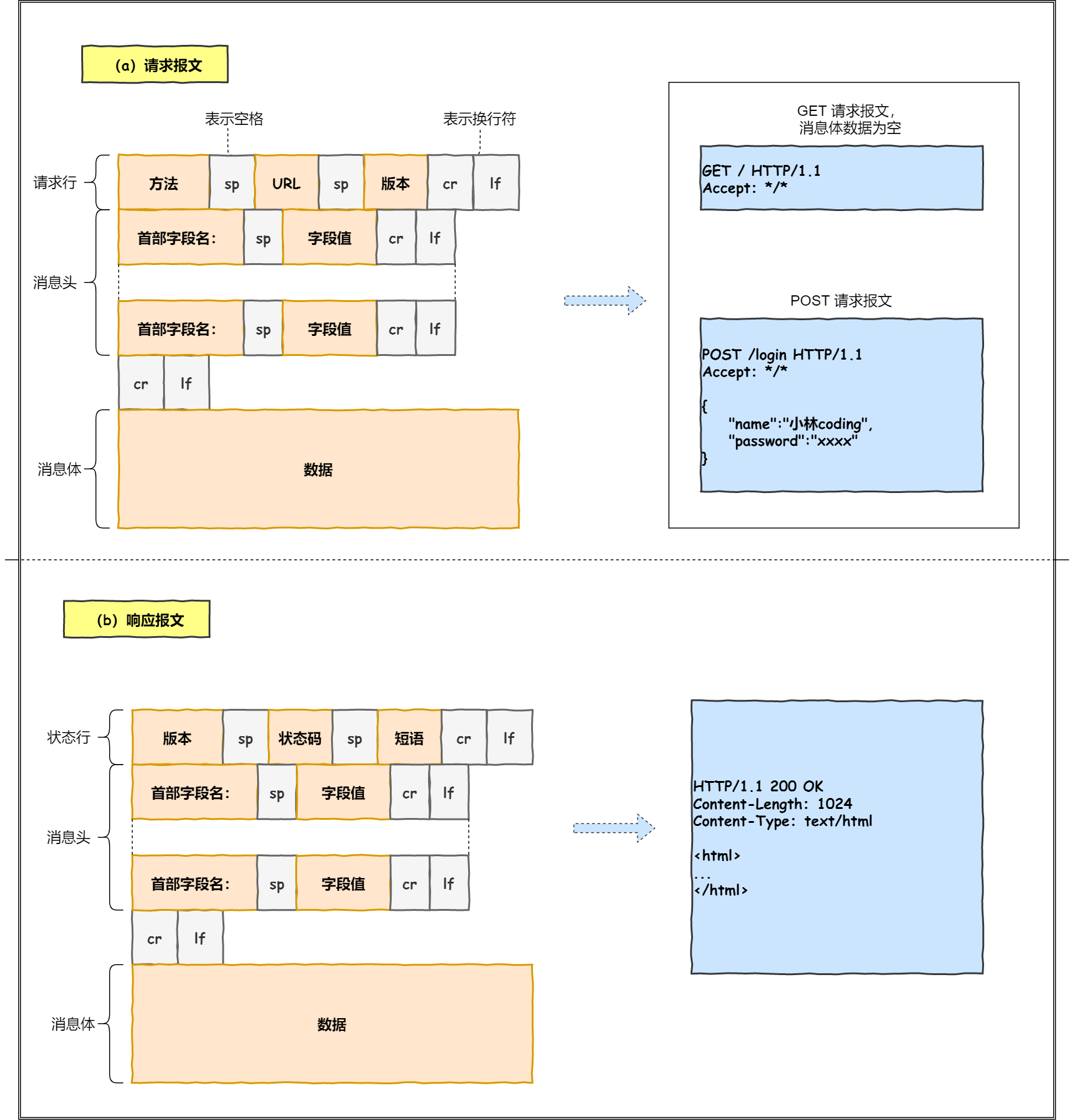
首先浏览器需要对URL进行解析,从而生成发送给Web服务器的请求信息
1 | |
URL实际上是请求服务器里的文件资源
对URL进行解析后,浏览器确定Web服务器和文件名,接下来就是根据这些信息来生成HTTP请求消息
DNS
通过浏览器解析URL并生成HTTP消息后,需要委托操作系统将消息发送给Web服务器,在发送之前需要完成查询服务器域名对应的IP地址
1 | |
根域名DNS服务器信息保存在所有互联网DNS服务器中.客户端只要能够找到任意一台DNS服务器,就可以通过它找到根域名DNS服务器.
- 域名解析的工作流程
1 | |
DNS域名解析结果缓存
浏览器首先看有没有对该域名的缓存,没有就去查看操作系统有没有该域名缓存,没有再去查看本地系统的hosts文件,没有再去问[本地DNS服务器]
协议栈
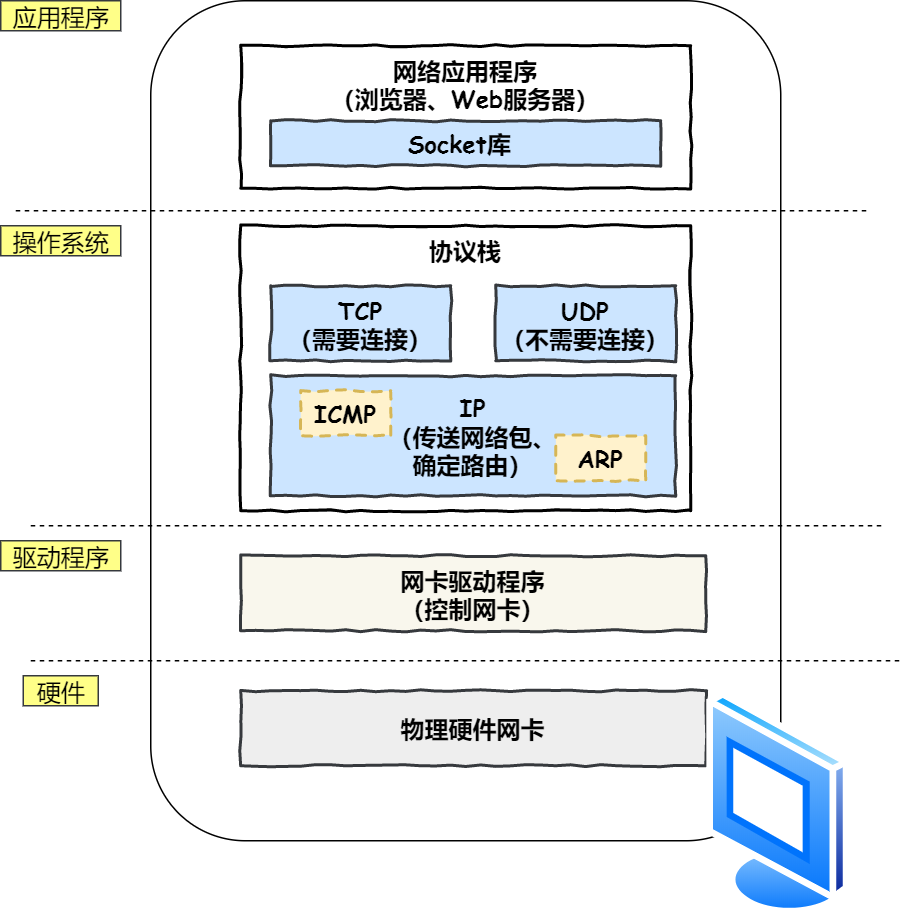
应用程序(浏览器)通过调用Socket库,来委托协议栈工作,协议栈的上半部分有两个部分,分别是负责收发数据的TCP和UDP协议,这两个传输协议会接收应用层的委托收发数据
协议栈的下面一半是用于IP协议控制网络包收发操作,在互联网上传数据时,数据会被切分一块块网络包.将网络包发送给对方的操作由IP协议负责,ICMP协议用于告知网络包传送过程中产生的错误以及各种控制信息. ARP协议用于根据IP地址查询响应的以太网MAC地址.
TCP - 可靠传输
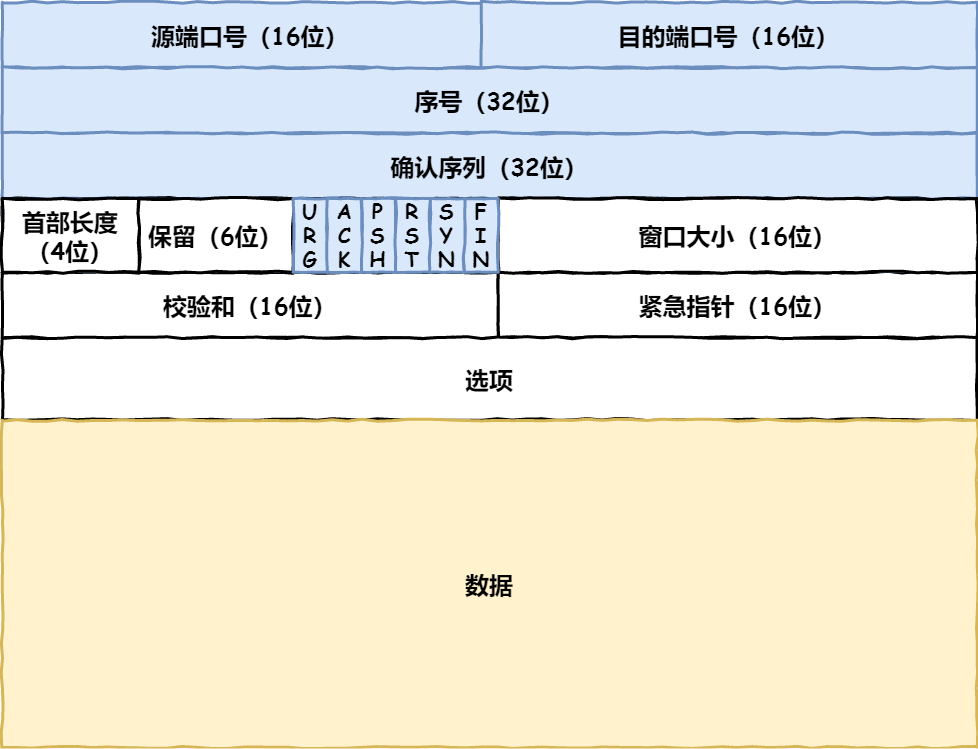
- TCP报文头部格式
1 | |
1 | |
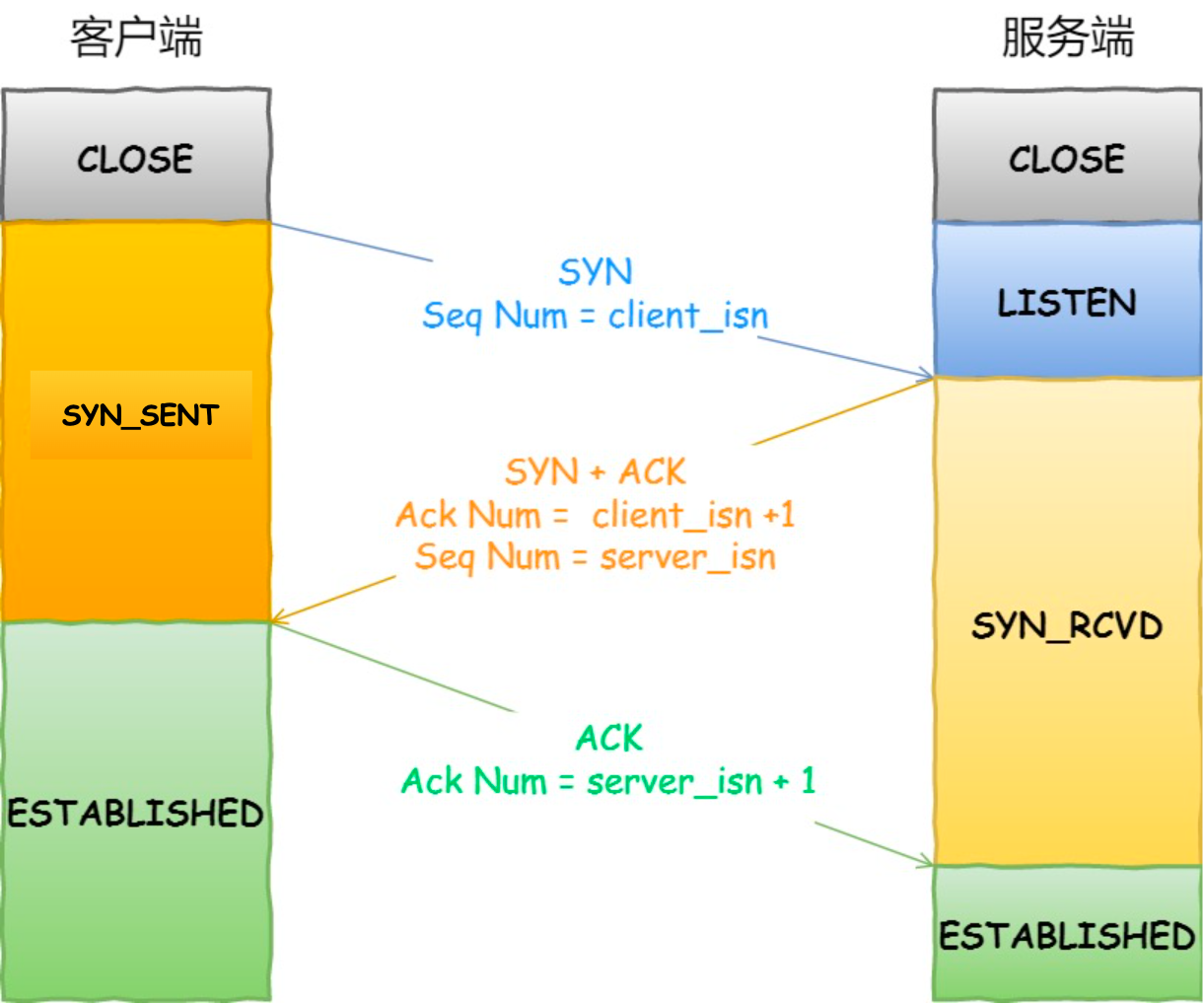
三次握手目的是保证双方都有发送和接收的能力
TCP的连接状态查看在Linux可以通过netstat -napt命令查看
1 | |
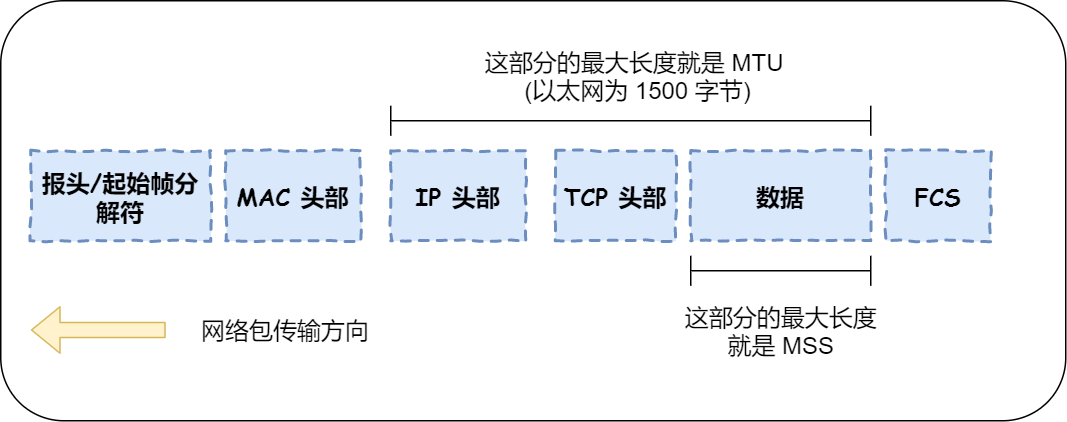
MTU: 一个网络报的最大长度,以太网中一般为1500字节MSS: 除去IP和TCP头部之后,一个网络报所能容纳的TCP数据的最大长度
IP
TCP在执行连接、收发、断开等各各阶段操作时,都需要委托IP模块将数据封装成网络包发送给通信对象
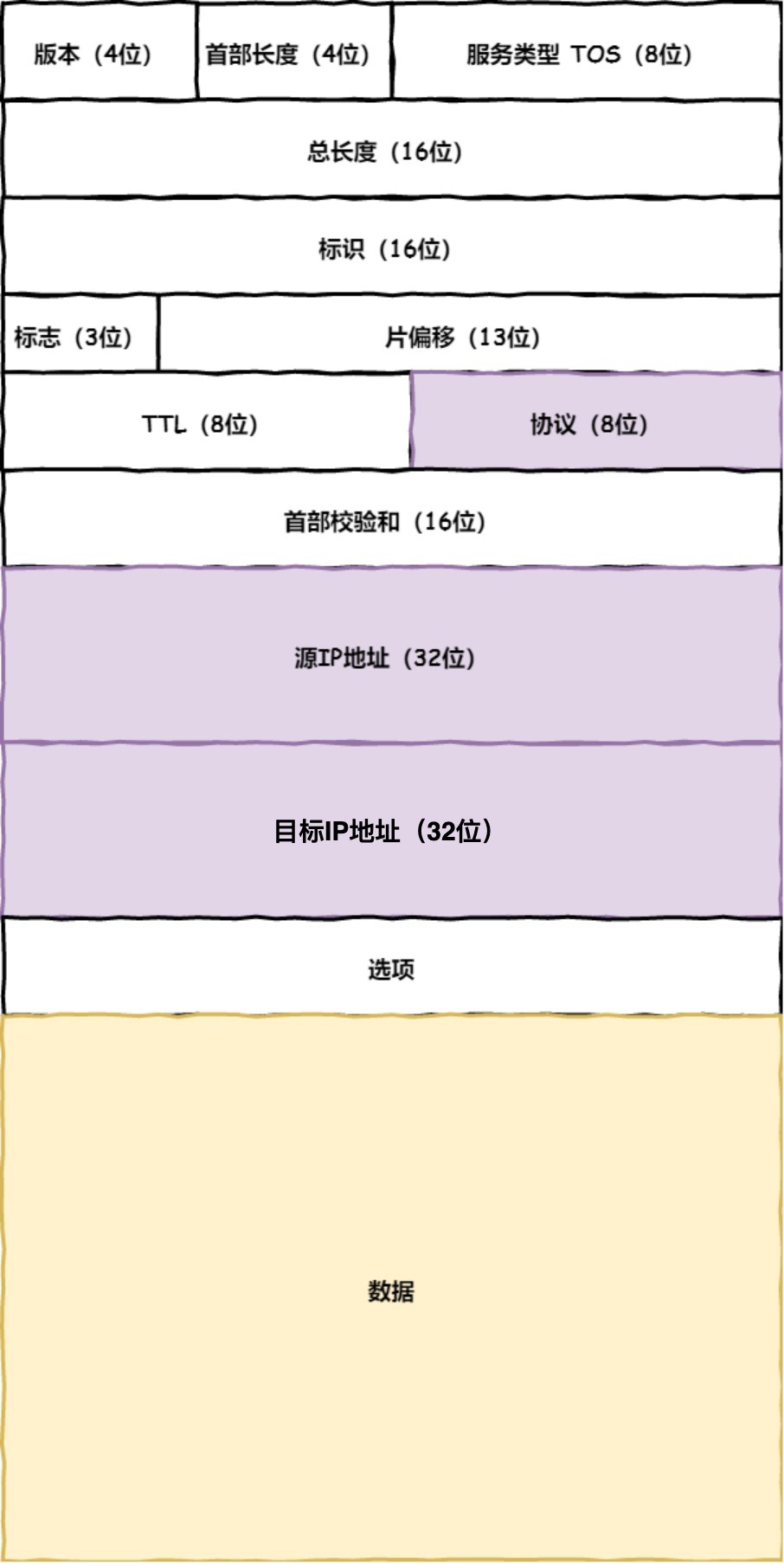
源地址IP: 客户端输出IP地址目标地址: 通过DNS域名解析得到的Web服务IP
Linux操作系统可以使用route -n命令查看当前系统的路由表
1 | |
MAC
生成IP头部之后,接下来网络包还需要在IP头部的前面加上MAC头部.
在Mac包需要发送方MAC地址和接收方目标MAC地址,用于两点之间的传输。一般在TCP/IP通信中,MAC包头的协议类型只使用:
1 | |
- ARP 协议
ARP协议会在以太网中以广播的形式,
使用arp -a 查看ARP缓存内容
1 | |
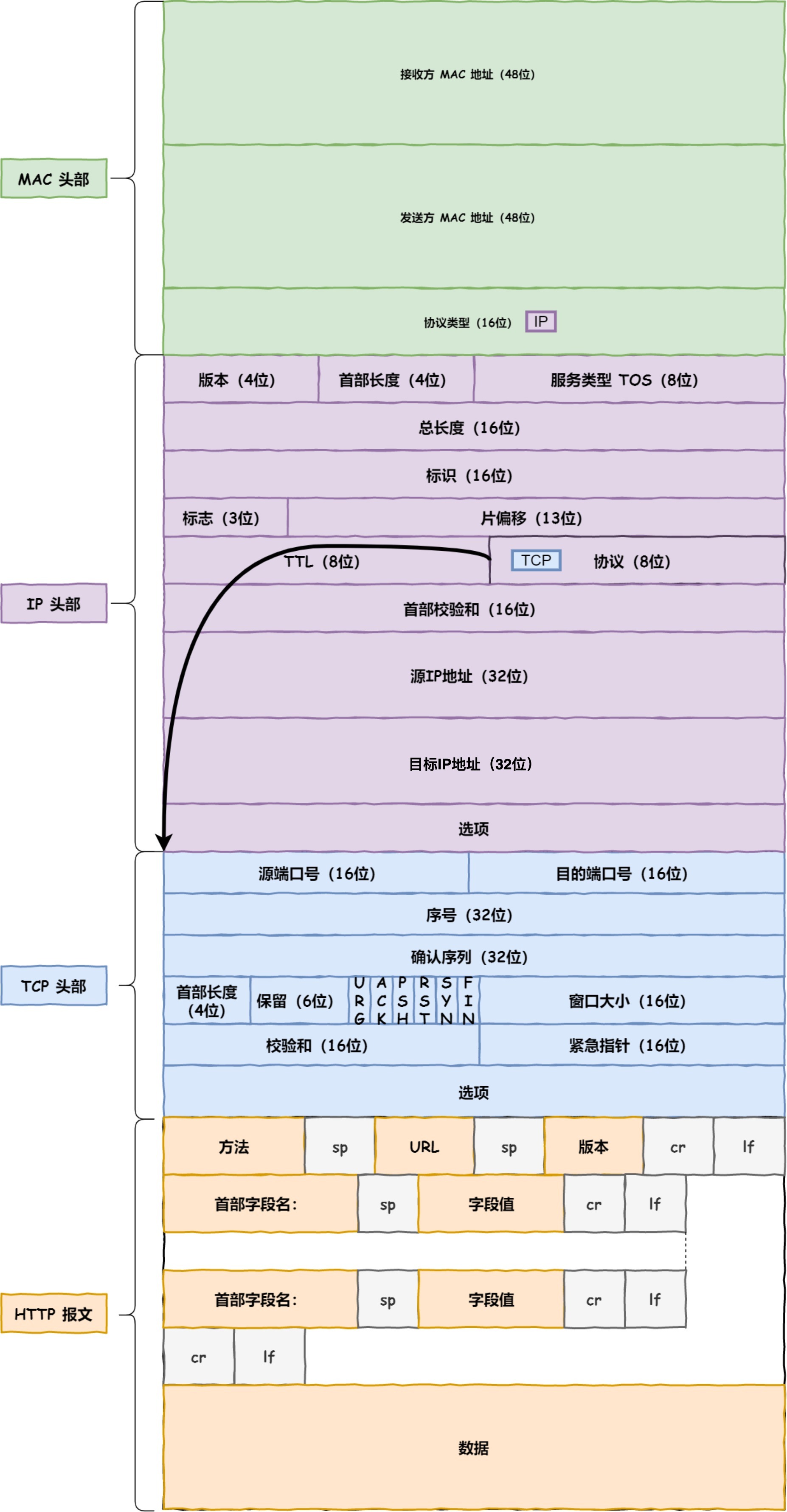
网卡
网络包只是存放在内存中的一串二进制数字信息,没有办法直接发送给对方,因此需要将数字信息转换为电信号,负责执行这一操作的时网卡,要控制网卡还需要靠网卡驱动程序.
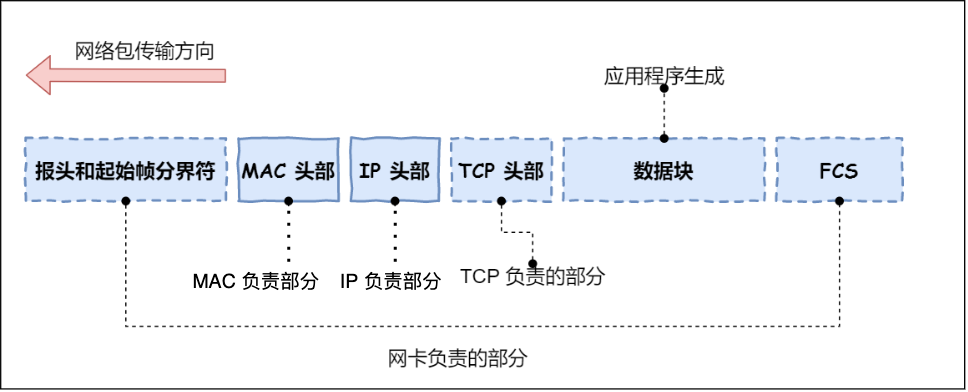
网卡驱动获取网络包之后,会将其复制到网卡内的缓存中,接着会在其开头加上报头和起始帧分界符,在末尾加上用于检测错误的帧校验序列.
交换机
交换机设计是将网络包原样转发到目的地,交换机工作在MAC层,称为二层网络设备.交换机接收所有包并存放在缓冲区后,查询这个包的接收方MAC地址是否MAC地址表中有记录. 交换机的MAC地址主要包含两个信息:
1 | |
交换机根据MAC地址表查找MAC地址,然后将信号发送到相应的端口.
路由器
路由器是基于IP设计的,俗称三层网络设备,路由器的各个端口都具有MAC地址和IP地址
交换机是基于以太网设计的,俗称二层网络设备,交换机的端口不具有MAC地址
HTTP
HTTP基本概念
HTTP (HyperText Transfer Protocol) 超文本传输协议
HTTP常见的状态吗?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
191xx: 提示信息,表示目前是协议处理的中间状态,还需要后续的操作
2xx: 成功,报文已经收到并正确的处理
200 OK: 表示一切正常
204 No Content: 响应头没有body数据
206 Partial Content: 应用于HTTP分块下载或断点续传,表示响应返回的body数据并不是资源的全部,而是其中的一部分,也是服务器处理成功的状态
3xx: 重定向,资源位置发生变动,需要客户端重新发送请求
301 Moved Permanently: 永久重定向,说明请求的资源已经不存在,需改进新的URL再次访问
302 Found: 表示临时重定向,说明请求的资源还在,但暂时需要用另一个URL来访问
301,302都会在响应头里使用字段Location,指明后续要跳转的URL,浏览器会自动重定向新的URL
304 Not Modified: 表示资源为修改,重定向已经存在的缓冲文件
4xx: 客户端错误,请求报文有误,服务器无法处理
400 Bad Request: 表示客户端请求的报文有错误
403 Forbidden: 表示服务器禁止访问资源
404 Not Found: 表示请求的资源在服务器上不存在
5xx: 服务器错误,服务器在处理请求时内部发生了错误
500 Internal Server Error: 服务器错误(笼统通用的错误码)
501 Not Implemented: 表示客户端请求的功能还不支持
502 Bad Gateway: 通常是服务器作为网管或者代理时返回的错误码,表示服务器自身工作正常,访问后段服务器发生错误
503 Service Unavailable: 表示服务器当前很忙,暂时无法响应客户端HTTP常见字段?
1 | |
- GET与POST
1 | |
- HTTP缓存技术
1 | |
GET与POST
HTTP特性
HTTP缓存技术
HTTPS与HTTP
HTTP/1.1 HTTP/2 HTTP/3 演变
Apache vs Nginx
Nginx采用事件驱动架构,可在一个线程中处理多个请求,相比之下,Apache会为每个请求创建一个线程,由于Nginx采用了”多请求-单线程”设计,Nginx可在用户请求量增加时保持持续的响应性能,在某些评估中,Nginx的性能比Apache高出2.5倍,而资源消耗却与Apache类似.
网上关于Apache和Nginx性能比较的文章非常多,基本有如下定论:
- Nginx在并发性能上比Apache强很多,如果时纯静态资源(图片、js、css)那么Nginx时不二之选
- Apache有mod_php,在PHP类的应用场景下比Nginx部署起来简单很多,一些老的PHP项目用Apache来配置运行非常简单,例如Wordpress
- Nginx的模块比较容易写,可以通过C的mod实现接口性质的服务,并且有用惊人的性能,分支OpenRestry可以配合Lua来实现很多自定义功能,兼顾扩展性和性能.
网络编程的历史
最原始的网络编程伪代码
1
2
3
4
5
6listen(port) # 监听在接收服务的端口上
while True: # 一直循环
conn = accept() # 接收链接
read_content = read(conn) # 读取连接发送过来的请求
response = process(conn) # 执行业务逻辑,并得到客户端回应的内容
conn.write(response) # 将回应写回给连接最原始的Linux中accept,read,write调用都是阻塞,这就导致以上代码只能同时处理一个连接.
每个连接开一个进程
1 | |
使用子进程来处理连接,父进程继续等待连接进来,但这种方式有如下两个明显的缺陷:
- fork()调用比较费时,需要对进程进行内存拷贝,即使现在Linux普遍引入COW(Copy on Write)技术(fork的时候不做内存拷贝,只有其中一个副本发生Write的时候才进行copy)加速了fork()的效率,但fork依旧是个比较”重的系统调用”
- 较多的内存占用,也是由于上述的内存复制造成的
每个连接开线程
引入进程/线程池
计算机领域“空间换时间”,即用使用更多内存的方式换取更快的运行速度.事先创建出很多进程/线程,就像一个池子,这样虽然会浪费一部分的内存,但连接过来的时候就省去开启进程/线程的时间.
但这种方式会有一个缺陷:当并发数大于进程/线程池的大小的时候,性能就会发生很大的下滑:
非阻塞网络编程
- select() vs poll()
select()是在1983年首次出现在4.2版的BSD Unix中,poll()出现的稍微晚,1997年在Linux内核2.1.23版本中加入. select()只能处理小于等于1024的文件描述符.
select:
1 | |
poll
1 | |
- epoll()
epoll是Linux内核的可扩展I/O事件通知机制,它设计目的只在取代既有POSIX select与poll系统函数.让需要大量操作文件描述符的程序发挥更优异的性能(select,poll系统函数花费的事件复杂度为O(n),epoll耗时O(1)). epoll与FreeBSD的kqueue类似,底层都是由可配置的操作系统内核对象构建,并以文件描述符形式呈现用户空间.
1 | |
事件通知API
libevent是一个一步事件处理软件函式库,libevent提供了一组应用程序编程接口(API),让程序员可以设定某些事件发生时所执行的函式。libevent可以取代网络服务器使用的事件循环检测框架. 按照libevent的官方网站,libevent库提供一下功能,当一个文件描述符的特定事件(可读、可写、或出错)发生时,或一个定时事件发生时,libevent就会自动执行用户指定的回调函数,来处理事件.
一个基于libevent网络server,这有助于event-driven programming(事件驱动编程)
- 水平触发LT(level-triggered) & 边沿触发ET(edge-triggered)
1 | |
TCP socket 安全问题
- 在Internet环境下,安全问题分为如下几类:
- 信息传输过程中被黑客窃取
- 服务器自身的安全
- 服务端数据的安全
首先,如果能用https,就尽量用https,能用nginx等常见服务器,就用常见服务器,主要能避免以下问题:
- 自己实现的协议&Server端可能会有各种Bug,被缓冲区溢出攻击等
- SSL加密体系在防监听方面已经足够成熟,值得信赖
工程实现过程中,要考虑:
- 各种可能的缓冲区溢出攻击
- SYN flood攻击,慢连接攻击
- DDoS防起来有难度,但至少能防御DoS攻击
业务逻辑层面,要考虑:
- 每个接口都要做好用户&权限验证
- 接口会不会被乱用,重放攻击
- 攻击方会不会找到一个比较消耗服务端资源的接口,用很小的代价耗尽服务端资源
- 你的服务会不会被黑客利用去攻击别的服务,特别是会根据用户输入抓取什么资源的服务
- 古老的SQL注入
- 无耻的仿冒服务,DNS欺诈
- 涉及HTML的,还要考虑跨站…
长连接&连接池
TCP是基于连接的协议,其实这个”连接”只是一个逻辑上的概念,在IP层看来,TCP和UDP仅仅是内容上稍有差别而已.TCP协议仅仅是连接的两端对于四元组和sequence号的一种约定而已.
1 | |
- HTTP长连接
HTTP长连接,HTTP持久连接(HTTP persistent connection, 也称为HTTP keep-alive或HTTP connection reuse)是使用同一个TCP连接发送和接收多个HTTP请求/应答,而不是为每一个新的请求/应答打开新的连接的方式.
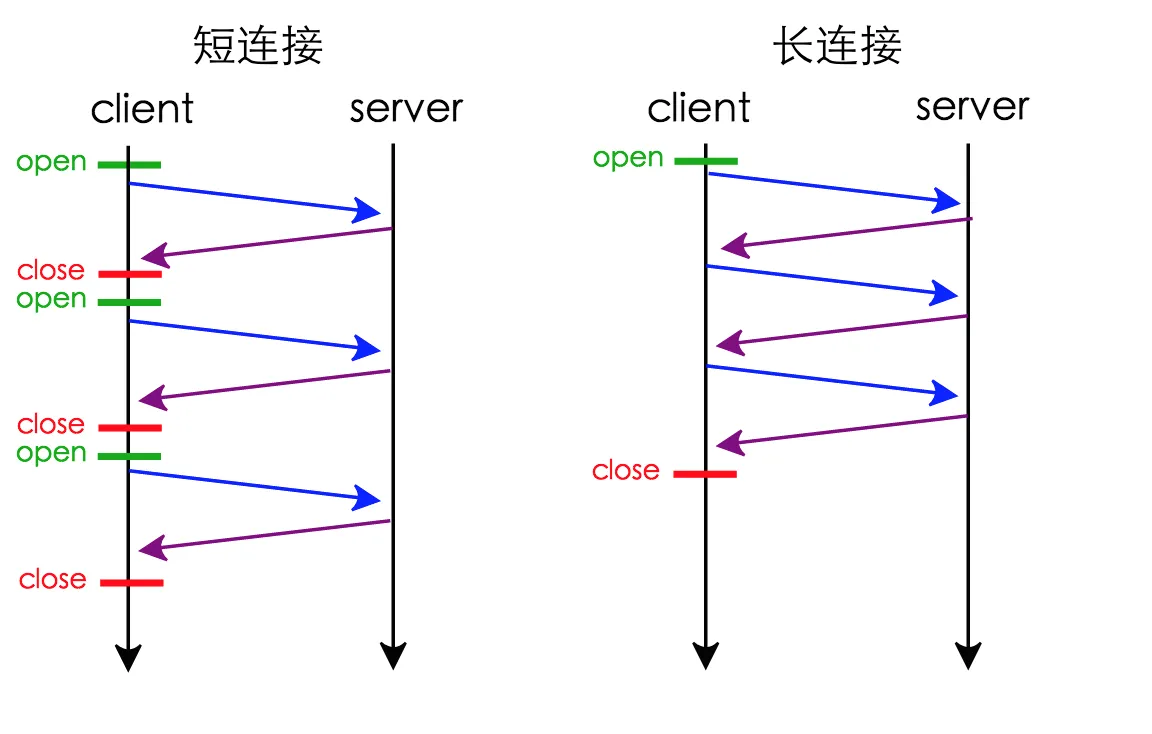
- Keep-Alive的优势
- 较少的CPU和内存的使用(由于同时打开的连接的减少)
- 允许请求和应答的HTTP管线化
- 减少后续请求的延迟(无需再进行握手)
- 报告错误无需关闭TCP连接
- Keep-Alive的劣势
- 对于单个文件被不断请求的服务,Keep-Alive可能会极大的影响性能,因为它在文件被请求之后还保持不必要的连接很长时间.
- 动静分离
对于静态资源的请求,HTTP请求头里的Cookie等信息没有用处,反而占用了宝贵的上行网络资源,用独立的域名存放静态资源后,请求静态资源域名就不会默认带上主域的Cookie,从而解决这个问题